Our Results at 512 Resolution
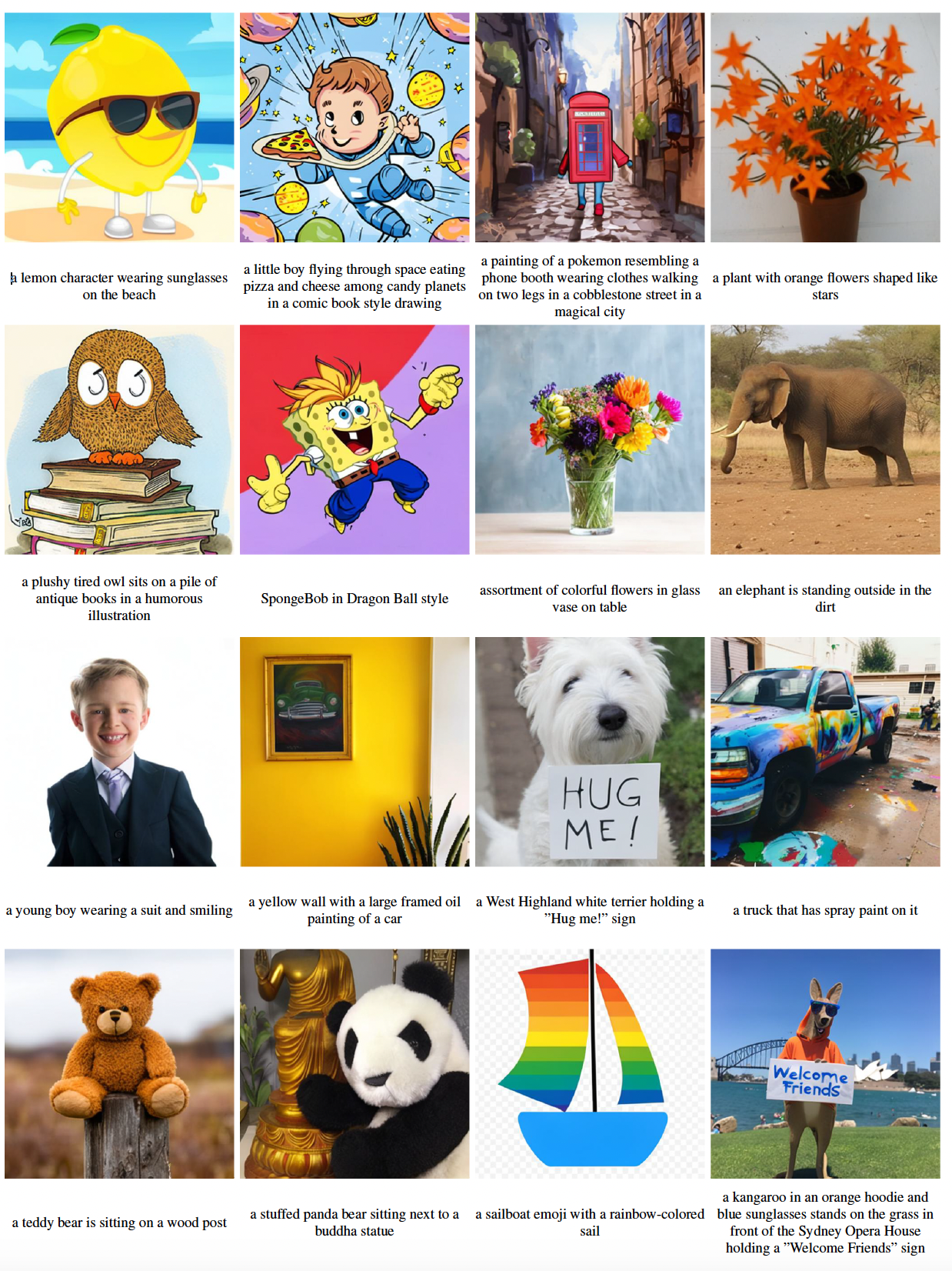
The input text prompts are shown below the images. Results are obtained from generative models trained for 290K steps.
The input text prompts are shown below the images. Results are obtained from generative models trained for 290K steps.
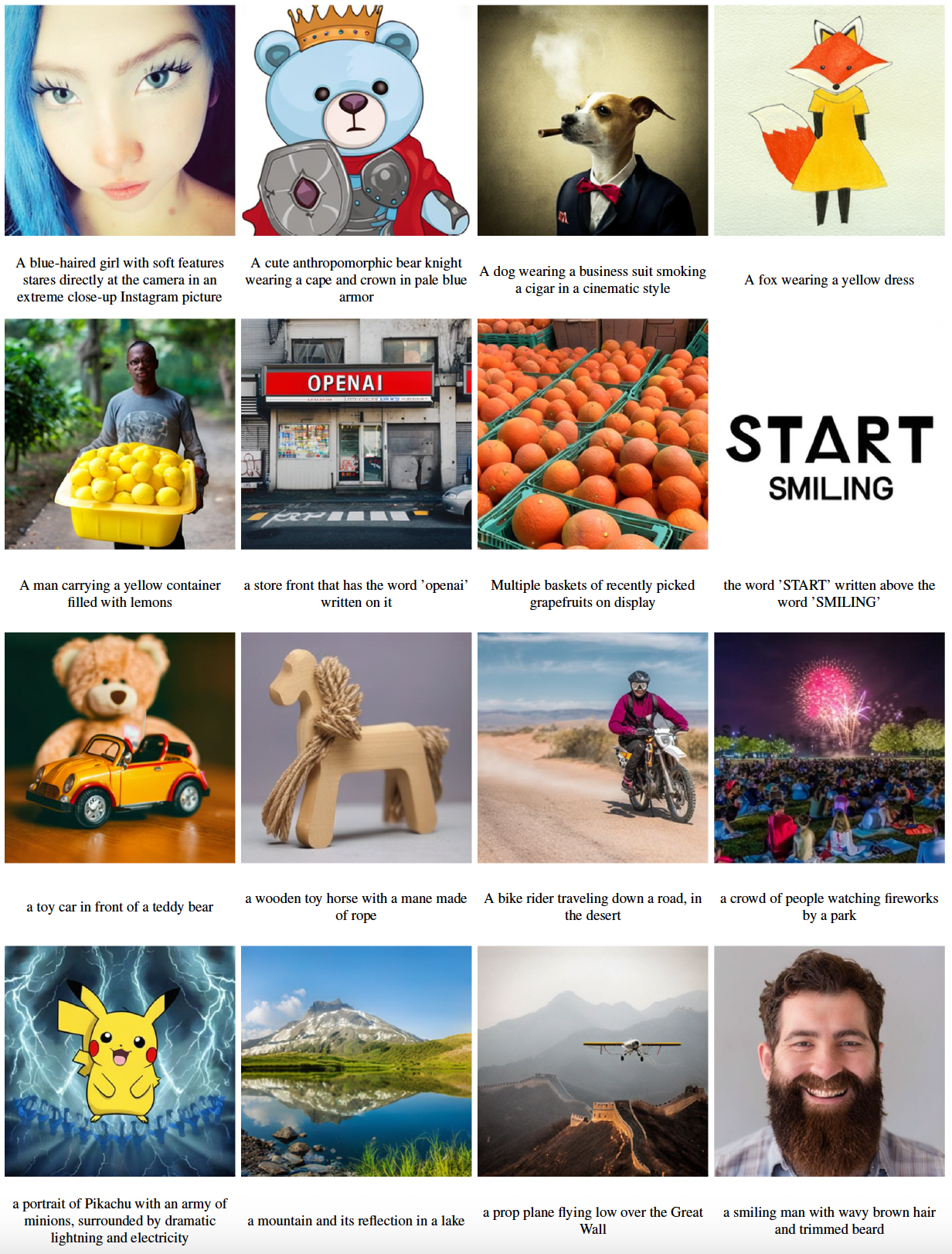
The input text prompts are shown below the images. Results are obtained from generative models trained for 290K steps.

The input text prompts are shown below the images. Results are obtained from generative models trained for 290K steps. Rows 1 and 2 show 512 x 640 (3:4), row 3 and 4 show 512 x 768 (2:3), and row 5 shows 512 x 910 (9:16).
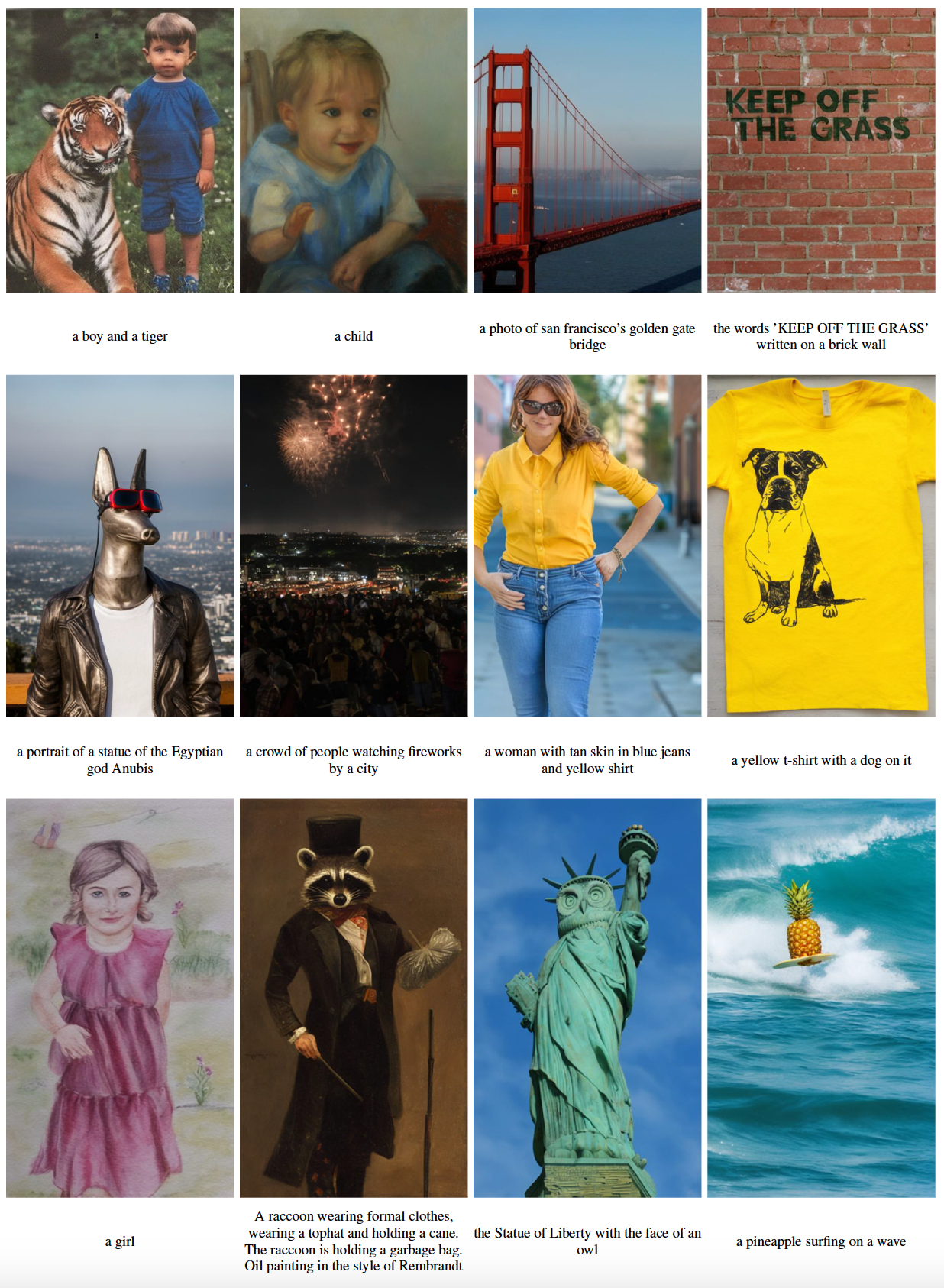
The input text prompts are shown below the images. Results are obtained from generative models trained for 290K steps. Rows 1 and 2 show 640 x 512 (4:3), rows 3 and 4 show 768 x 512 (3:2), and row 5 shows 910 x 512 (16:9).