Aligning Visual Foundation Encoders to Tokenizers for Diffusion Models
Abstract
In this work, we propose aligning pretrained visual encoders to serve as tokenizers for latent diffusion models in image generation. Unlike training a variational autoencoder (VAE) from scratch, which primarily emphasizes low-level details, our approach leverages the rich semantic structure of foundation encoders. We introduce a three-stage alignment strategy: (1) freeze the encoder and train an adapter and a decoder to establish a semantic latent space; (2) jointly optimize all components with an additional semantic preservation loss, enabling the encoder to capture perceptual details while retaining high-level semantics; and (3) refine the decoder for improved reconstruction quality. This alignment yields semantically rich image tokenizers that benefit diffusion models. On ImageNet 256x256, our tokenizer accelerates the convergence of diffusion models, reaching a gFID of 1.90 within just 64 epochs, and improves generation both with and without classifier-free guidance. Scaling to LAION, a 2B-parameter text-to-image model trained with our tokenizer consistently outperforms FLUX VAE under the same training steps. Overall, our method is simple, scalable, and establishes a semantically grounded paradigm for continuous tokenizer design.
Key Idea
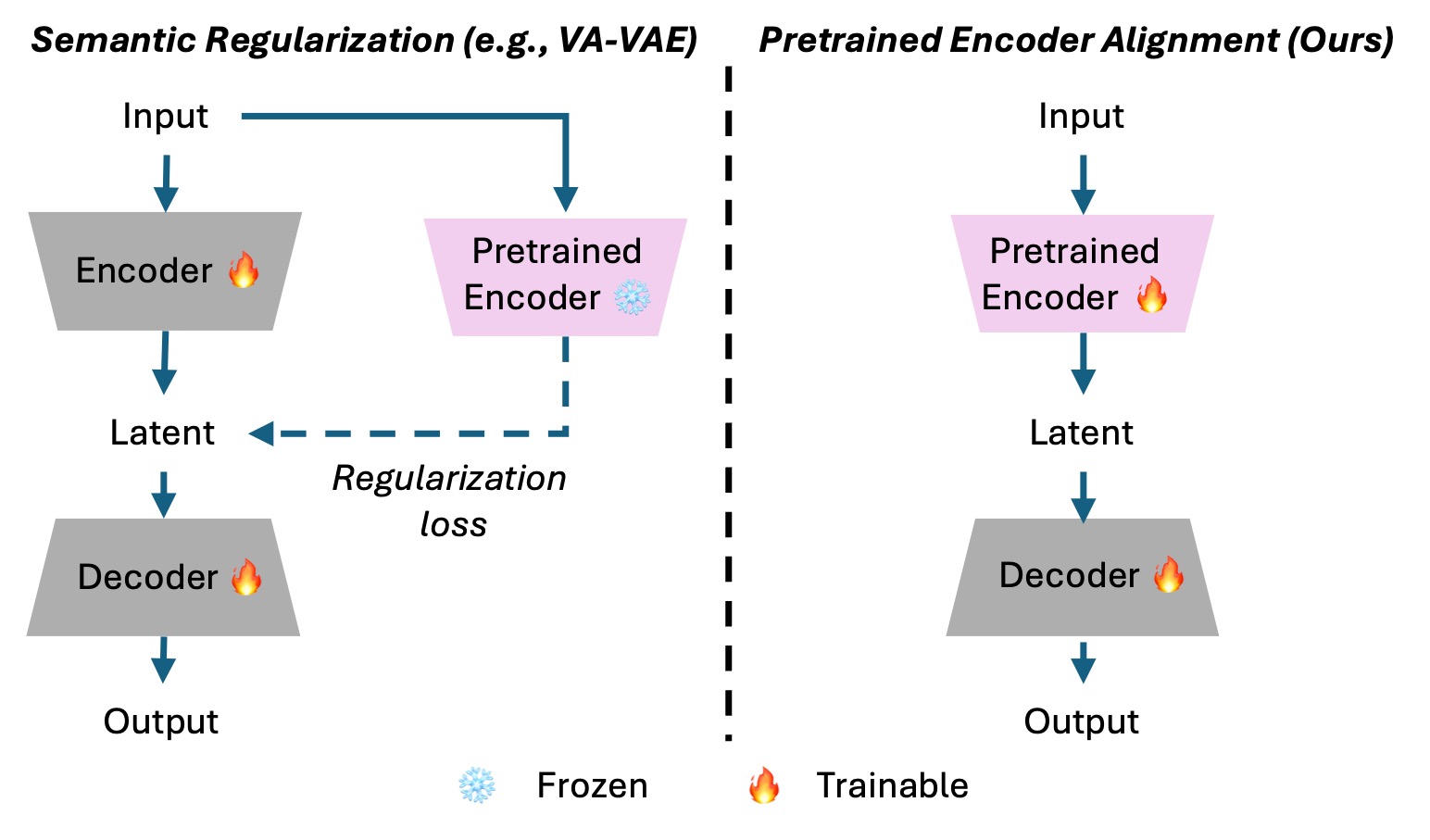
Our goal is to design an image tokenizer with stronger semantic grounding -- hence better diffusability -- with competitive reconstruction ability. Our intuition is that learning semantic is inherently more difficult than learning reconstruction. Thus, we take a different perspective: rather than forcing the encoder to learn semantics from scratch like previous work (left), we align a pretrained visual foundation encoder (e.g., DINOv2) to a visual tokenizer (right). Since the encoder already captures rich semantic structure, our alignment makes the first task -- learning a diffusion-friendly latent space (i.e., achieving strong diffusability) -- much easier.
Three-Stage Alignment
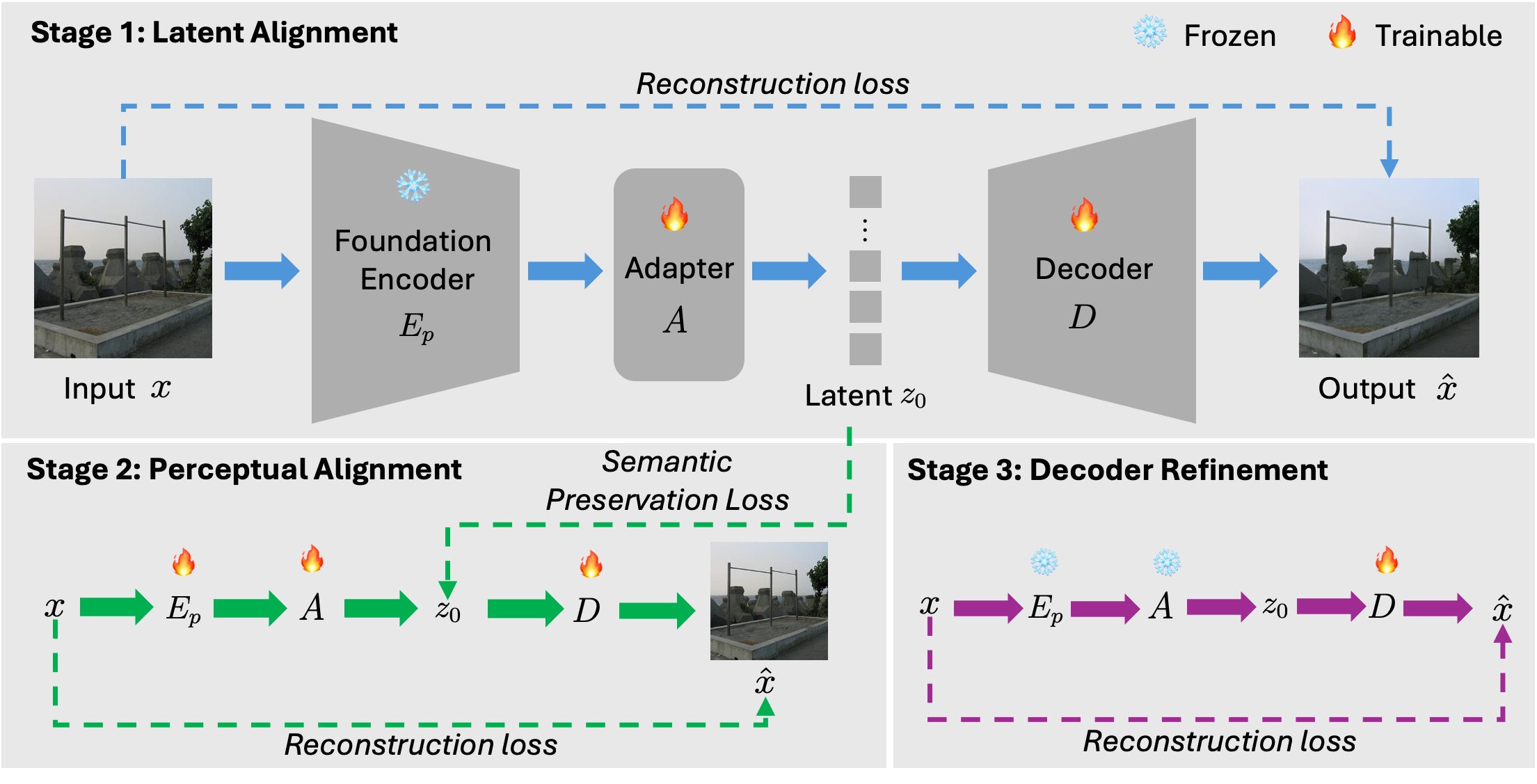
Stage 1: Latent Alignment (top).
The pretrained encoder is kept frozen, while the adapter and decoder are trained with reconstruction loss to align its output into a semantically grounded latent space for generation.
Stage 2: Perceptual Alignment (bottom left).
All components are optimized jointly to enrich the latent space with low-level details, while a semantic preservation loss ensures that it retains high-level semantics.
Stage 3: Decoder Refinement (bottom right).
Only the decoder is fine-tuned with reconstruction loss to enhance reconstruction fidelity.
Results on ImageNet 256x256
Comparison of Sampling Steps, CFG Scales, Convergence Speed
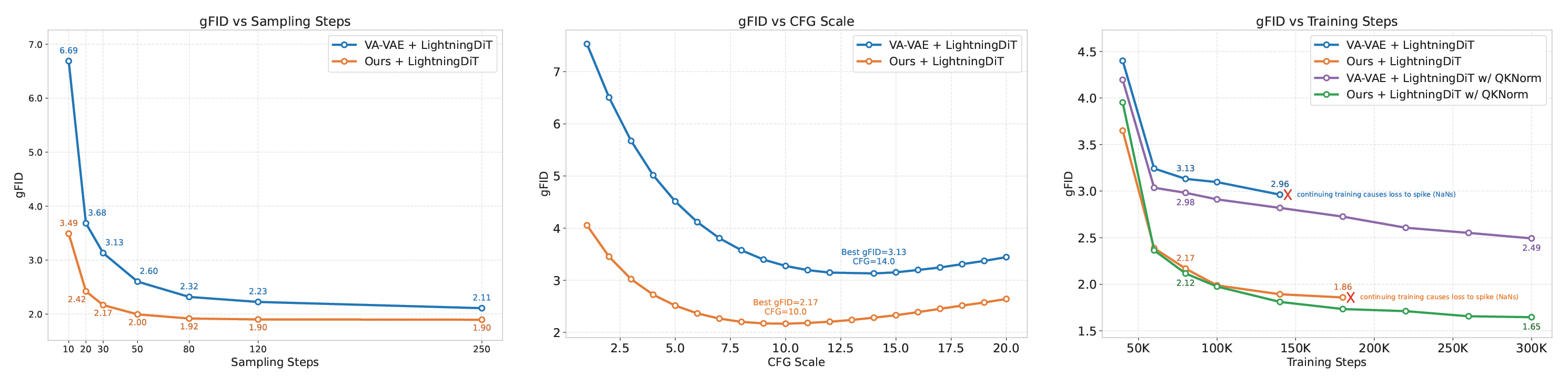
Left: effect of sampling steps versus gFID at 80K training steps. Middle: effect of CFG scale versus gFID at 80K training steps with 30 sampling steps. Right: effect of training steps versus gFID with 30 sampling steps. QKNorm is enabled during extended training to ensure stability. All gFIDs in the left and right figures are reported using the best-searched CFG scale. Our method has faster convergence speed and achieves better results with fewer sampling steps and smaller CFG scales.
System-Level Comparison
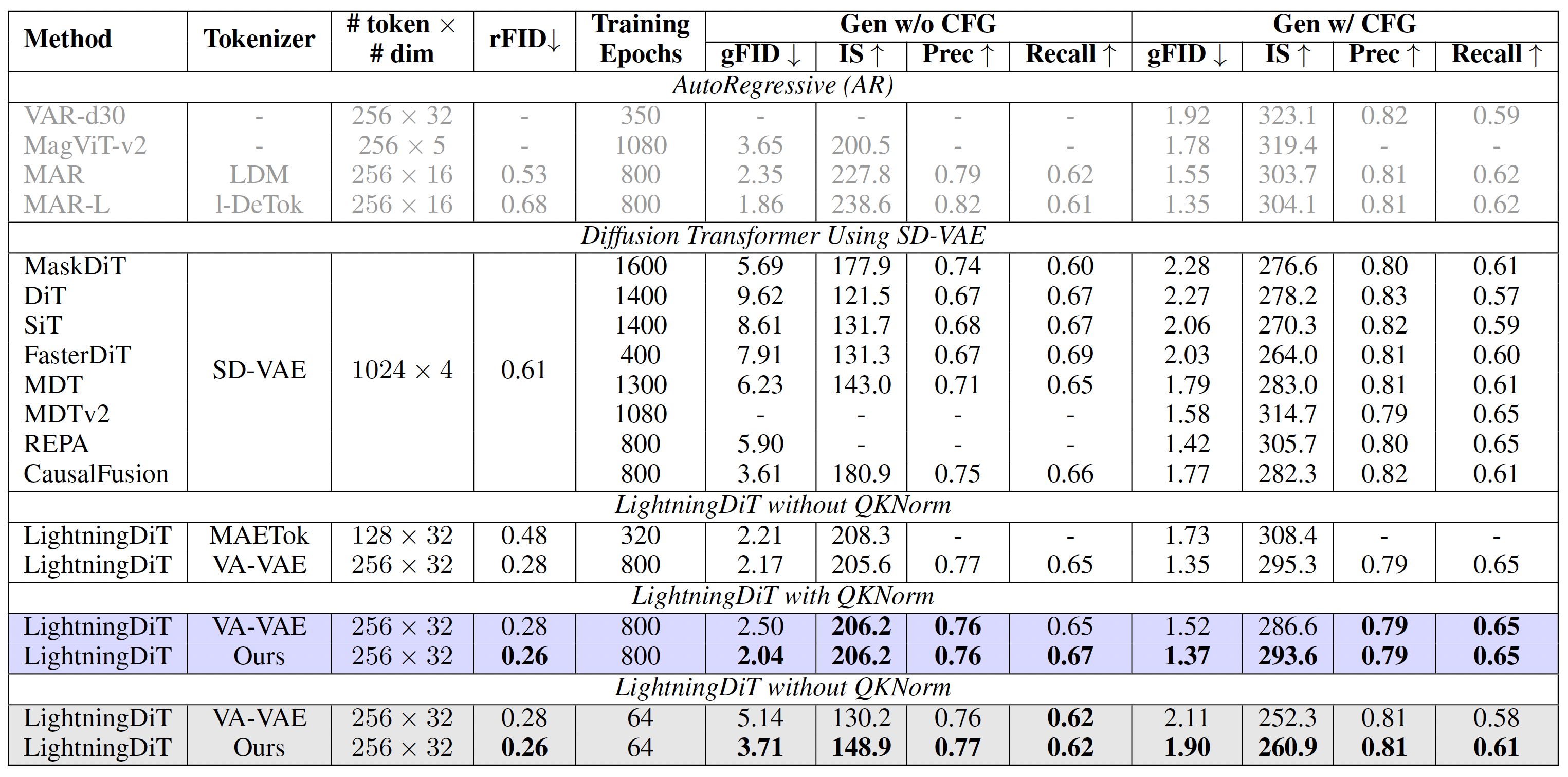
Gray and purple regions refer to LightningDiT trained for 64 epochs (80K training steps, no QKNorm) and 800 (1M training steps, with QKNorm) epochs, respectively. Bold numbers indicate the best result in each color block. When comparing our method to VA-VAE at 64 epochs (80K training steps), we surpass it in both reconstruction and generation quality, highlighting our superior convergence speed. For the 800-epoch setting (1M training steps), we retrain LightningDiT of VA-VAE using the official repository with QKNorm enabled -- necessary to avoid loss spikes, but slightly degrade generative performance, as noted by the authors. Our method (with QKNorm) achieves a gFID of 1.37, outperforming VA-VAE’s 1.52 (with QKNorm) and comparable to the original VA-VAE result of 1.35 (without QKNorm) reported in their paper.
Results on Text-To-Image Generation
Comparison with FLUX VAE at 256x256 Resolution
Click for More Results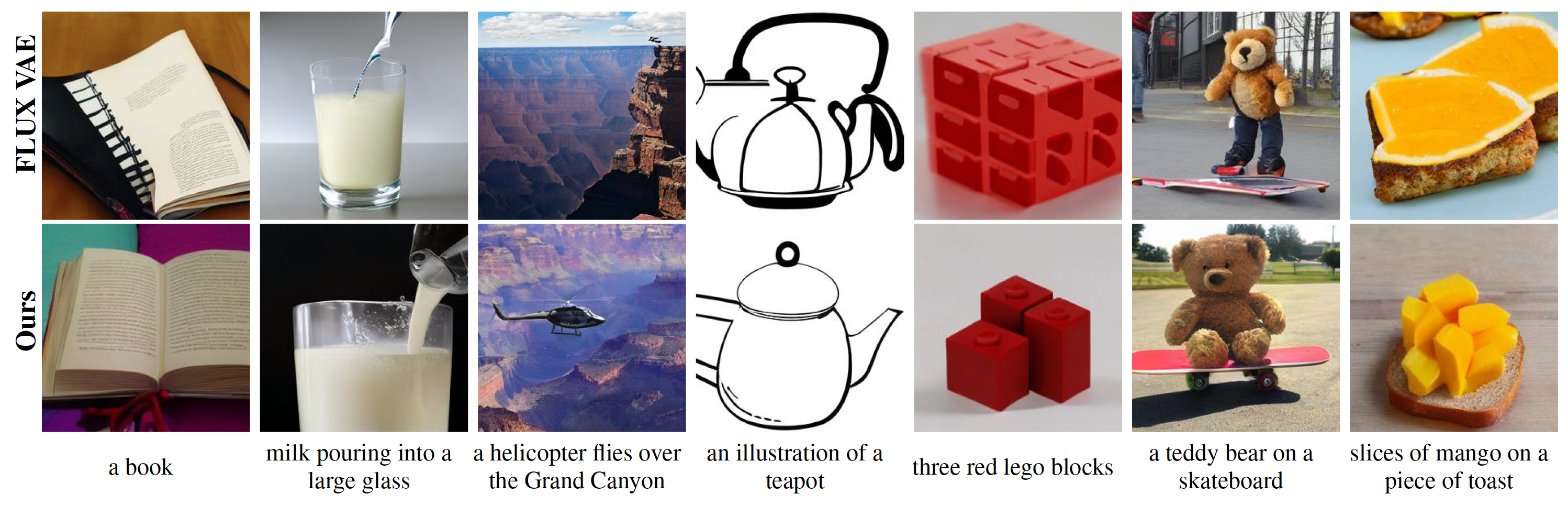
Input text prompts are shown below the images and results are generated from generative models trained for 100K steps. Our method (bottom row) produces images with better coherence and prompt alignment compared to the one using FLUX VAE (top row).
Our Results at 512 Resolution
Click for More Results
The input text prompts are shown below the images. Results are obtained from diffusion models trained for 290K steps. The first four are square images, and the final one has a 4:5 aspect ratio.
Acknowledgements
Special thanks to Yuqun Wu, Yuanhao "Harry" Wang for their help in proofreading the paper.
This work was done while Bowei Chen and Tianyuan Zhang were interning at Adobe. We would like to thank Hailin Jin for his valuable support throughout the internship.